
SAN FRANCISCO, Nov. 12, 2025 (GLOBE NEWSWIRE) -- Today, MLCommons® announced new results for the MLPerf® Training v5.1 benchmark suite, highlighting the rapid evolution and increasing richness of the AI ecosystem as well as significant performance improvements from new generations of systems.
The MLPerf Training benchmark suite comprises full system tests that stress models, software, and hardware for a range of machine learning (ML) applications. The open-source and peer-reviewed benchmark suite provides a level playing field for competition that drives innovation, performance, and energy efficiency for the entire industry.
Increasing diversity of processors, increasing scale of systems, better performance on key benchmarks
Version 5.1 set new records for diversity of the systems submitted. Participants in this round of the benchmark submitted 65 unique systems, featuring 12 different hardware accelerators and a variety of software frameworks. Nearly half of the submissions were multi-node, which is an 86% increase from the version 4.1 round one year ago. The multi-node submissions employed several different network architectures, many incorporating custom solutions.
This round recorded substantial performance improvements over the version 5.0 results for two benchmark tests focused on generative AI scenarios, outpacing the rate of improvement predicted by Moore’s Law.
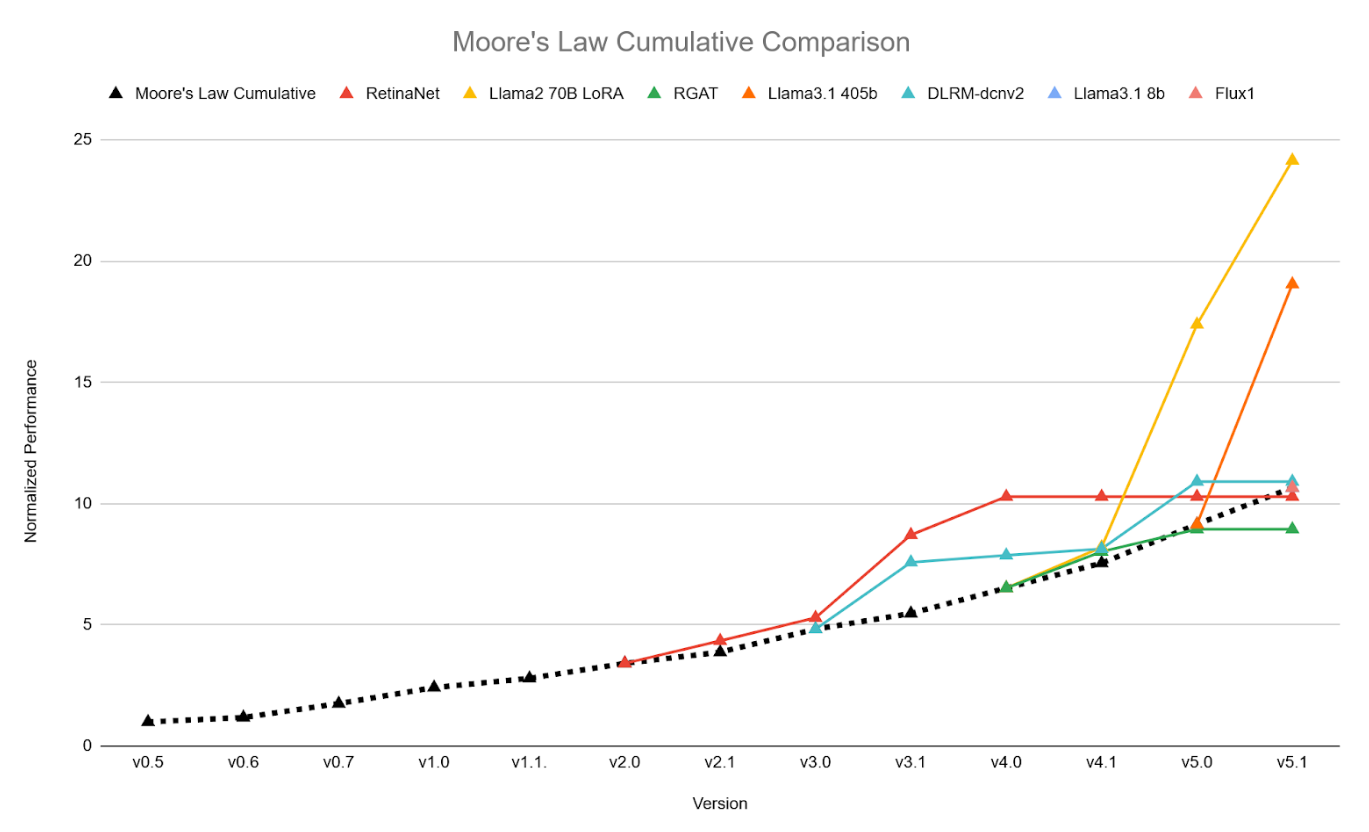 Relative performance improvements across the MLPerf Training benchmarks, normalized to the Moore’s Law trendline at the point in time when each benchmark was introduced.
Relative performance improvements across the MLPerf Training benchmarks, normalized to the Moore’s Law trendline at the point in time when each benchmark was introduced.
“More choices of hardware systems allow customers to compare systems on state-of-the-art MLPerf benchmarks and make informed buying decisions,” said Shriya Rishab, co-chair of the MLPerf Training working group. “Hardware providers are using MLPerf as a way to showcase their products in multi-node settings with great scaling efficiency, and the performance improvements recorded in this round demonstrate that the vibrant innovation in the AI ecosystem is making a big difference.”
Record industry participation points to broad ecosystem, driven by generative AI
The MLPerf Training v5.1 round includes performance results from 20 submitting organizations: AMD, ASUSTeK, Cisco, Datacrunch, Dell, Giga Computing, HPE, Krai, Lambda, Lenovo, MangoBoost, MiTAC, Nebius, NVIDIA, Oracle, Quanta Cloud Technology, Supermicro, Supermicro + MangoBoost, University of Florida, Wiwynn. “We would especially like to welcome first-time MLPerf Training submitters, Datacrunch, University of Florida, and Wiwynn” said David Kanter, Head of MLPerf at MLCommons.
The pattern of submissions also shows an increasing emphasis on benchmarks focused on generative AI (genAI) tasks, with a 24% increase in submissions for the Llama 2 70B LoRA benchmark, and a 15% increase for the new Llama 3.1 8B benchmark over the test it replaced (BERT). “Taken together, the increased submissions to genAI benchmarks and the sizable performance improvements recorded in those tests make it clear that the community is heavily focused on genAI scenarios, to some extent at the expense of other potential applications of AI technology,” said Kanter. “We’re proud to be delivering these kinds of key insights into where the field is headed that allow all stakeholders to make more informed decisions.”
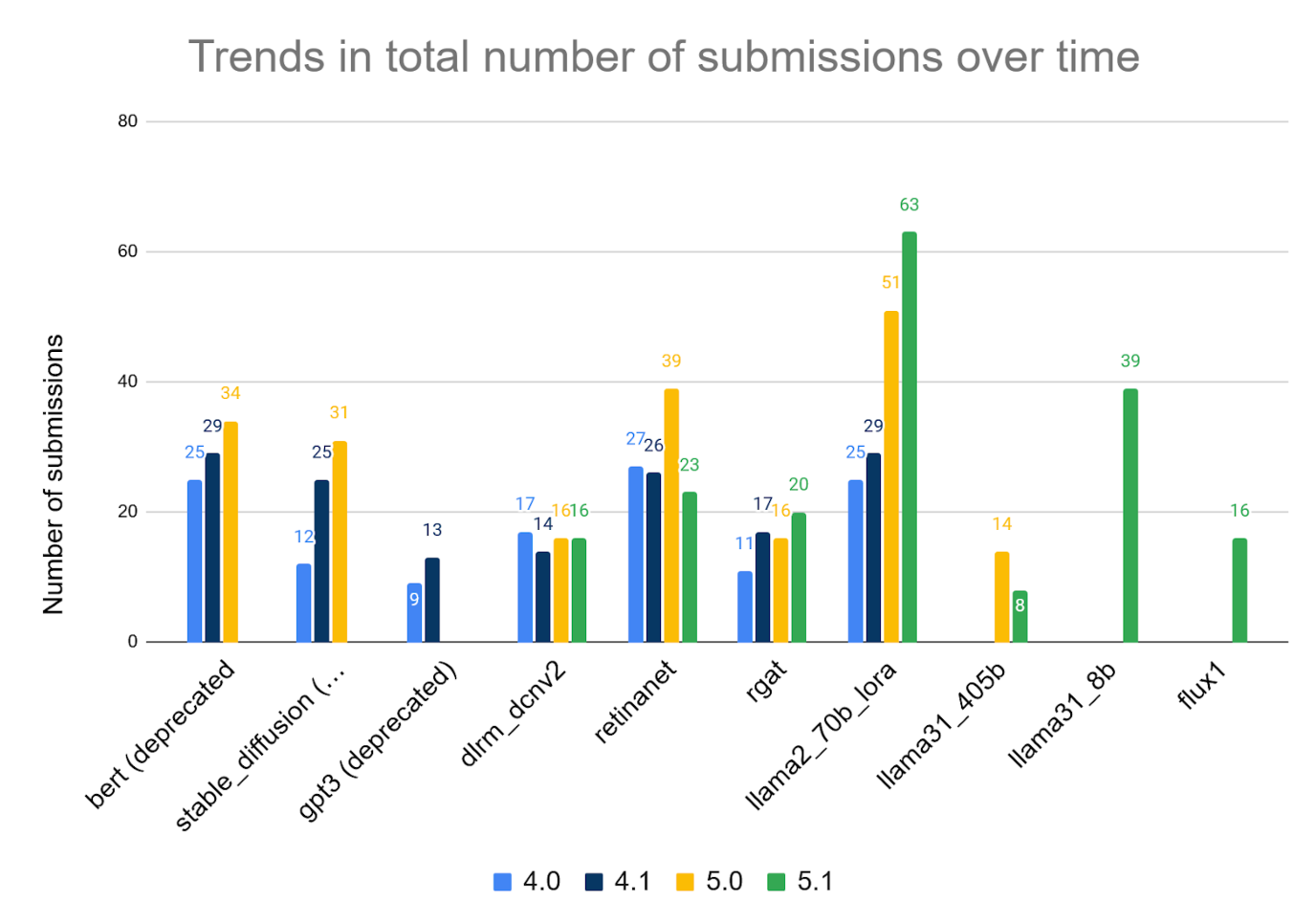
Robust participation by a broad set of industry stakeholders strengthens the AI ecosystem as a whole and helps to ensure that the benchmark is serving the community’s needs. We invite submitters and other stakeholders to join the MLPerf Training working group and help us continue to evolve the benchmark.
MLPerf Training v5.1 upgrades two benchmarks
The collection of tests in the suite is curated to keep pace with the field, with individual tests added, updated, or removed as deemed necessary by a panel of experts from the AI community.
In the 5.1 benchmark release, two previous tests were replaced with new ones that better represent the state-of-the-art technology solutions for the same task. Specifically: Llama 3.1 8B replaces BERT; and Flux.1 replaces Stable Diffusion v2.
Llama 3.1 8B is a benchmark test for pretraining a large language model (LLM). It belongs to the same “herd” of models as the Llama 3.1 405B benchmark already in the suite, but since it has fewer trainable parameters, it can be run on just a single node and deployed to a broader range of systems. This makes the test accessible to a wider range of potential submitters, while remaining a good proxy for the performance of larger clusters. More details on the Llama 3.1 8B benchmark can be found in this white paper https://mlcommons.org/2025/10/training-llama-3-1-8b/.
Flux.1 is a transformer-based text-to-image benchmark. Since Stable Diffusion v2 was introduced into the MLPerf Training suite in 2023, text-to-image models have evolved in two important ways: they have integrated a transformer architecture into the diffusion process, and their parameter counts have grown by an order of magnitude. Flux.1, incorporating a transformer-based 11.9 billion–parameter model, reflects the current state of the art in generative AI for text-to-image tasks. This white paper https://mlcommons.org/2025/10/training-flux1/ provides more information on the Flux.1 benchmark.
“The field of AI is a moving target, constantly evolving with new scenarios and capabilities,” said Paul Baumstarck, co-chair of the MLPerf Training working group. “We will continue to evolve the MLPerf Training benchmark suite to ensure that we are measuring what is important to the community, both today and tomorrow.”
View the results
Please visit the Training benchmark page to view the full results for MLPerf Training v5.1 and find additional information about the benchmarks.
About ML Commons
MLCommons is the world’s leader in AI benchmarking. An open engineering consortium supported by over 125 members and affiliates, MLCommons has a proven record of bringing together academia, industry, and civil society to measure and improve AI. The foundation for MLCommons began with the MLPerf benchmarks in 2018, which rapidly scaled as a set of industry metrics to measure machine learning performance and promote transparency of machine learning techniques. Since then, MLCommons has continued using collective engineering to build the benchmarks and metrics required for better AI – ultimately helping to evaluate and improve AI technologies’ accuracy, safety, speed, and efficiency.
For additional information on MLCommons and details on becoming a member, please visit MLCommons.org or email participation@mlcommons.org.
Press Inquiries: contact press@mlcommons.org
Figures accompanying this announcement are available at
https://www.globenewswire.com/NewsRoom/AttachmentNg/472ccd2a-e9d4-4d75-8036-20e0d9a4b61d
https://www.globenewswire.com/NewsRoom/AttachmentNg/caf8c9af-749d-46b3-88d6-b0f8b99a925e

![]()